X86
Table of contents
Example
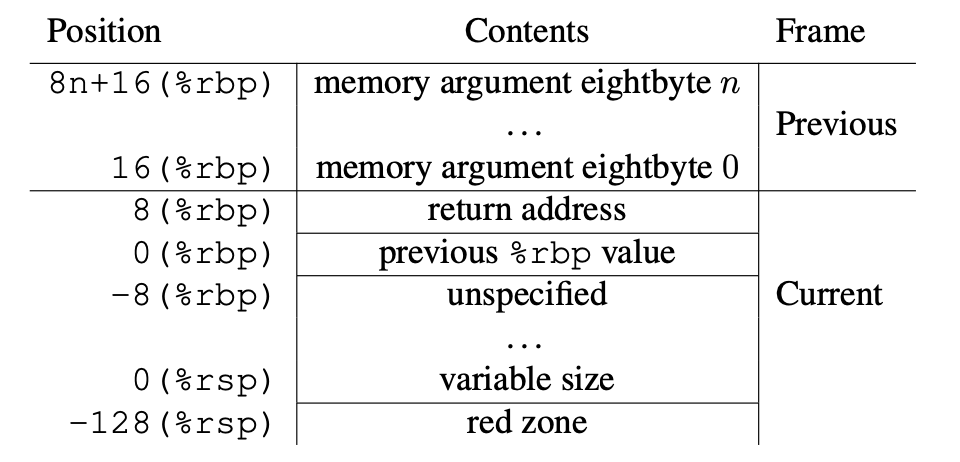
; make new call frame
; (some compilers may produce an 'enter' instruction instead)
push ebp ; save old call frame
mov ebp, esp ; initialize new call frame
; push call arguments, in reverse
; (some compilers may subtract the required space from the stack pointer,
; then write each argument directly, see below.
; The 'enter' instruction can also do something similar)
; sub esp, 12 : 'enter' instruction could do this for us
; mov [ebp-4], 3 : or mov [esp+8], 3
; mov [ebp-8], 2 : or mov [esp+4], 2
; mov [ebp-12], 1 : or mov [esp], 1
push 3
push 2
push 1
call callee ; call subroutine 'callee'
add eax, 5 ; modify subroutine result
; (eax is the return value of our callee,
; so we don't have to move it into a local variable)
; restore old call frame
; (some compilers may produce a 'leave' instruction instead)
; add esp, 12 ; remove arguments from frame, ebp - esp = 12.
; compilers will usually produce the following instead,
; which is just as fast, and, unlike the add instruction,
; also works for variable length arguments
; and variable length arrays allocated on the stack.
mov esp, ebp ; most calling conventions dictate ebp be callee-saved,
; i.e. it's preserved after calling the callee.
; it therefore still points to the start of our stack frame.
; we do need to make sure
; callee doesn't modify (or restores) ebp, though,
; so we need to make sure
; it uses a calling convention which does this
pop ebp ; restore old call frame
ret ; return
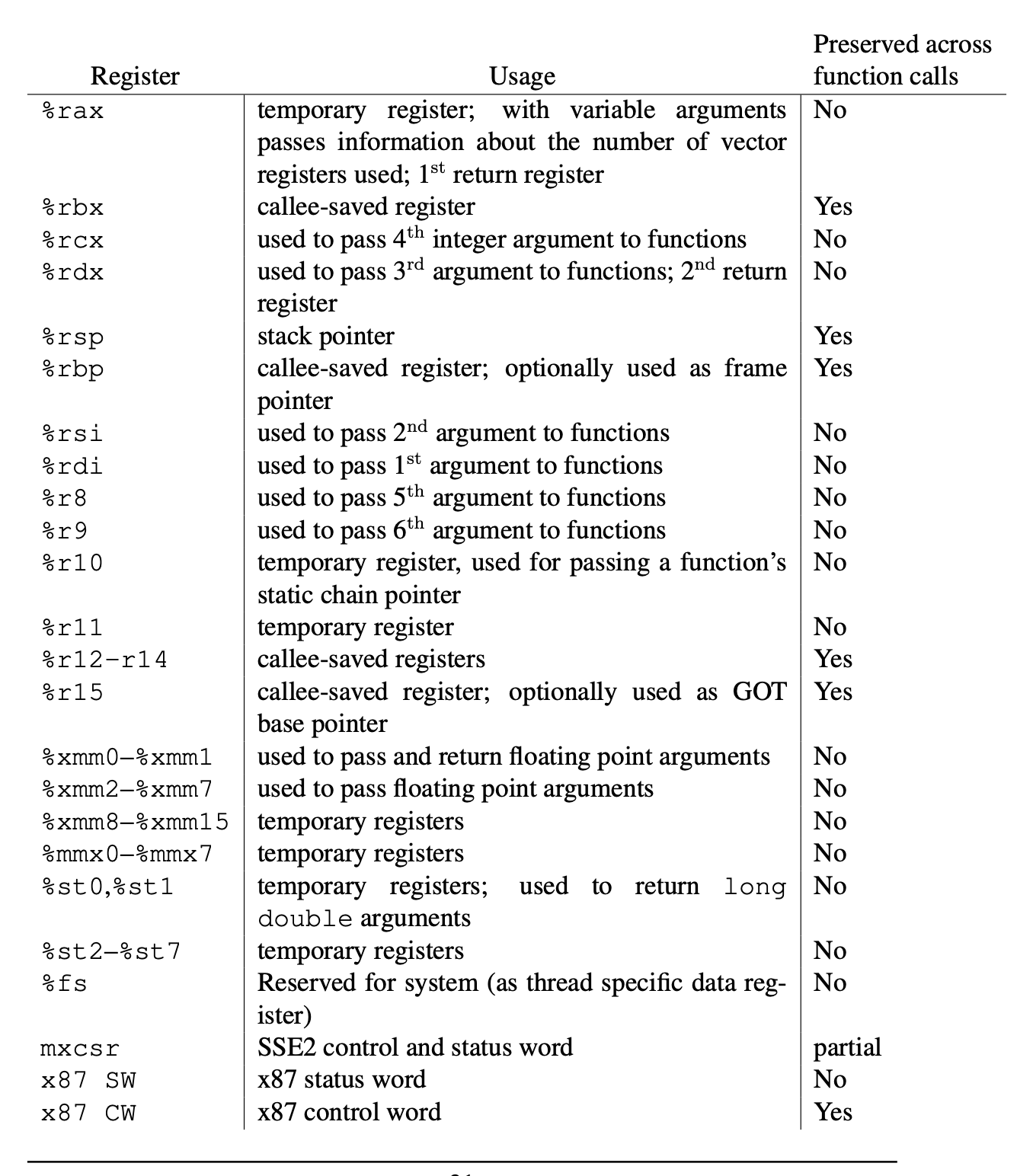
Registers
MMX
Sometimes, MMX is referred to as Matrix Math eXtensions.
The first set of SIMD extensions applied to Intel’s 80x86 instruction set, introduced in 1997.
- With the exception of
emms,movd, andmovq, all MMX instructions start with the letter ‘p’. - 8 64-bit general purpose registers called
MM0-MM7 - It uses the same register space as the FPU, so one cannot use MMX and floating point operations at the same time. The top 16 bits of each 80-bit FPU register are unused in MMX mode.
- It operates on single 64-bit quantities, 2 32-bit quantities, 4 16-bit quantities, or 8 8-bit quantities all at once
Instructions:
emms: Entering MMX mode is fairly simple; just execute an MMX instruction. Exiting MMX isn’t as simple. We use theemmsinstruction to perform this. (Because MMX uses the same register space with FPU, we introduce the concept of MMX mode)- Movement:
movd: leaves the top 32 bits zeromovq
- Boolean logic
pxor,por,pand,pandn(NAND)psllw/d/q,psrlw/d/q,psraw/dpaddb/w/d,paddsb(signed),paddusb(saturated at 255),subis similarpmullw,pmulhw(stores the upper 16 bits),pmaddwd
- Comparison
- Data Packing
packssdw: takes a register and another register or memory location, and saturates the 32-bit doublewords into 16-bit words. The doublewords and word results are signed.packsswb,packuswb(unsigned)
XMM Registers
Eight 128-bit XMM data registers were introduced into the IA-32 architecture with SSE extensions. They are named XMM0 to XMM7 and can be accessed independently from the x87 FPU and MMX registers and the general purpose registers.
SSE2
It was first introduced by Intel with the initial version of the Pentium 4 in 2000. It extends the earlier SSE instruction set, and is intended to fully replace MMX.
Instructions:
- Arithmetic:
addpd: adds 2 64-bit doublesaddsd: adds bottom 64-bit double.
- …
AVX
Announced by Intel in March of 2008. Initially, plans are for 16 256-bit registers, but it also extends to 512-bit registers with AVX-512. Whereas SSE registers are called XMM0-XMM7, AVX’s registers are called YMM0-YMM15. The XMM registers map to the bottom half of each of the larger YMM registers.
AVX repurposes many SSE instructions.