Linux Network Stack
Tools:
telnetnc
References:
This page is based on the Linux Kernel 4.19.101.
- Linux Kernel Networking Implementation and Theory
- Understanding Linux Network Internals
- Netfilter
- ip-xfrm(8)
- Glenn Herrin. Linux IP Networking, A Guide to the Implementation and Modification of the Linux Protocol Stack. 2000
Table of contents
The structure:
- BSD sockets (sys_socketcall)
- Netfilter / Nftables
- Network Protocol
- TCP / UDP
- IP
- Packet Scheduler
- Device Drivers
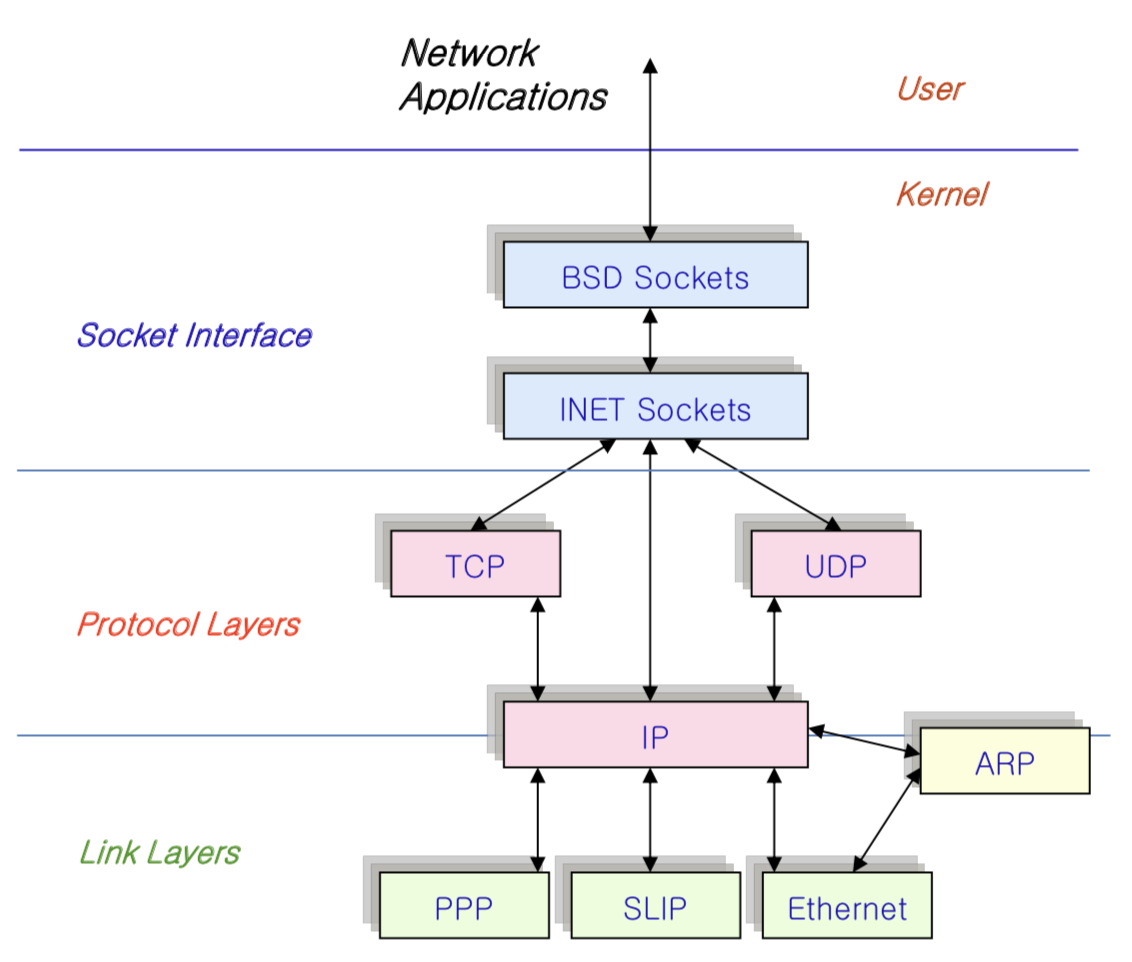
The init program runs the script /etc/init.d/networking which enables the networking.
Data Structures
struct proto_ops
for virtual dispatching
int familyint (*bind) (struct socket *sock, ...)and others
struct socket
an abstraction very close to user space, ie BSD sockets used to program network applications. Defined at /include/linux/net.h:110
struct file *file: File back pointer for gcsocket_state state: socket state (%SS_CONNECTED, etc)short type: socket type (%SOCK_STREAM, etc)const struct proto_ops *ops:struct socket_wq *wq;: wait queue for several usesstruct sock *sk;: internal networking protocol agnostic socket representation
struct sock
the network representation of a socket (also known as INET socket) Defined at /include/linux/sock.h:327
struct socket_wq __rcu *sk_wq: sock wait queue and async headu8 sk_shutdown: mask ofSEND_SHUTDOWNand/orRCV_SHUTDOWNatomic_t sk_drops: raw/udp drops counterstruct sk_buff_head sk_write_queueu32 sk_pacing_ratestruct sk_buff_head sk_receive_queuestruct sk_backlog {struct sk_buff *head, *tail; ...}u8 sk_protocol: which protocol this socket belongs in this network familyvoid (*sk_data_ready)(struct sock *sk)and others: callbackint sk_rcvbuf: size of receive buffer in bytesint sk_forward_alloc: space allocated forwardatomic_t sk_backlog.rmem_alloc- UDP: size of the space used for buffer recevied packets
atomic_t sk_drops: raw/udp drops counter__s32 sk_peek_off: current peek_offset valuelong sk_rcvtimeo: SO_RCVTIMEO
superclass: struct sock_common __sk_common (inet_timewait_sock)
subclass:
struct inet_sockdefined at/include/net/inet_sock.h:177struct udp_sockstruct sk_buff_head reader_queue ____cacheline_aligned_in_smp: udp_recvmsg try to use this before splicing sk_receive_queue
struct sk_buff
the representation of a network packet and its status. Defined in /include/linux/skbuff.h:665
struct list_head liststruct sock *sk;: Socket we are owned bystruct net_device *dev;: Device we arrived on/are leaving byunsigned char *head, *data: Head of buffer; Data head pointersk_buff_data_t tail, end: seealloc_skb()for details.unsigned int truesize: buffer sizechar cb[48] __aligned(8): control buffer, that is free to use for every layer- UDP:
struct sock_skb_cb { u32 dropcount; }
- UDP:
unsigned int truesize: the length of the variable size data component(s) plus the size of thesk_buffheader. This is the amount that is charged against the sock’s send or receive quota.unsigned int len: the size of a complete input packet, includeing data in the kmalloc’d part, fragment chain and/or unmapped page buffers.unsigned int data_len: the number of bytes in the fragment chain and in unmapped page buffers and is normally 0.
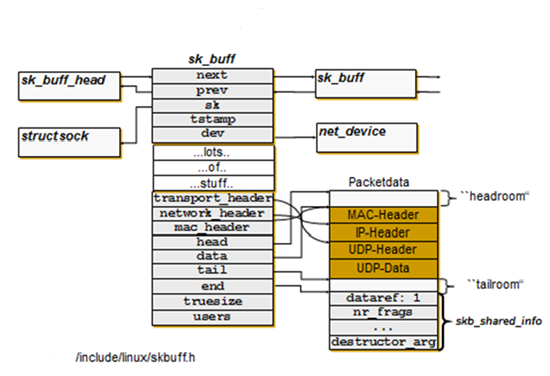
A buffer is linear if and only if all the data is contained in the kmalloc’d header. Here are some cases where the buffer is not linear (Probably 1/2 of the network code in the kernel is dedicated to dealing with the rarely used abomination):
- data is stored in different locations of physical pages (common in NIC driver model) (unmapped page buffers)
- IP packet fragmentation (fragment chain)
- large TCP data packets are cut into several MTU size
struct dst_entry
Defined in /include/net/dst.h. It denotes the route for this sk_buff; the route is determined by the routing subsystem.
int (*input)(struct sk_buff *):ip_local_deliver,ip_forward,ip_mr_input,ip_error,dst_discard_inint (*output)(struct net *net, struct sock *sk, struct sk_buff *skb);:ip_output,ip_mc_output,ip_rt_bug,dst_discard_out
struct net_device
Defined at /include/linux/netdevice.h:1747. It represents physical or virtual device (Every interface except aliasing interface is assigned a net_device). Actually, this whole structure is a big mistake. It mixes I/O data with strictly “high-level” data, and it has to know about almost every data structure used in the INET module. It is initialized by the device driver and the core kernel routines.
When the relationship of vitural device to real device is not one-to-one, the dev_queue_xmit may need to select the real device to use. Becasue QoS is enforced on a per-device basis.
Memory-mapped IO (MMIO): request_region, release_region
- Each network device is assigned a queuing discipline.
- bitmap
state: used by Traffic Control
- bitmap
unsigned int mtustruct netdev_rx_queue *_rxpossible_net_t nd_net;
struct net
network namspace. Defined at /include/net/net_namespace.h:51
struct net_protocol
Defined in /include/net/protocol.h:41. This is used to register protocols. extern struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS]
int (*handler)(struct sk_buff *skb)
example /net/ipv4/af_inet.c:1694:
static struct net_protocol udp_protocol = {
.early_demux = udp_v4_early_demux,
.early_demux_handler = udp_v4_early_demux,
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
.netns_ok = 1,
};
Packet Tour
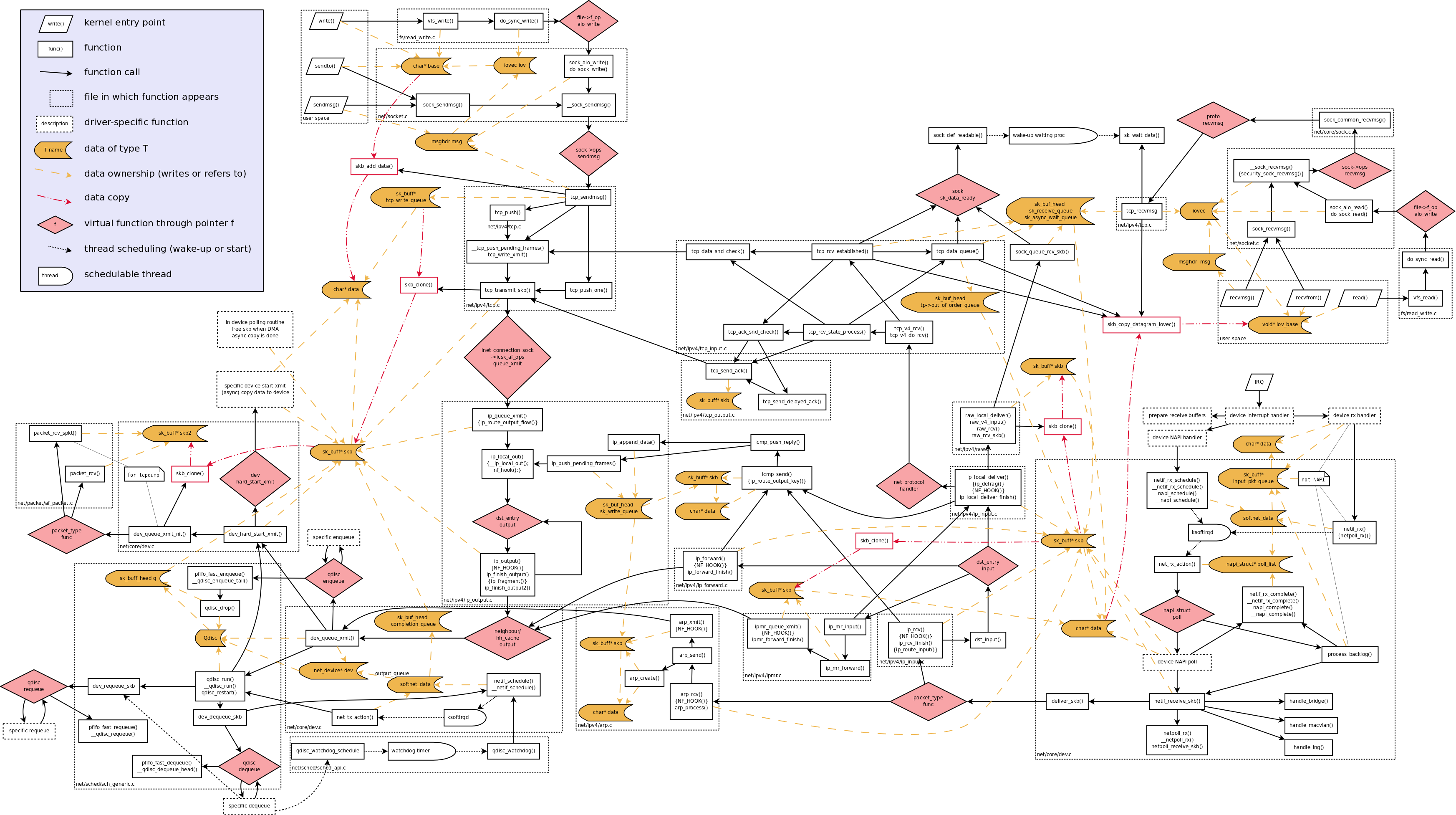
Receiving Packets:
- NAPI:
- maintain a
poll_listof devices that have new frames in the ingress queue. Devices in the list have interrupt disabled. The NAPI polls them in RR fashion and calls a virtual functionpollto dequeue buffers from the device’s ingress queue. core/dev.c:net_rx_actionis the main entry point of NAPI polling and is associated with theNET_RX_SOFTIQR.- Run with interrupts enabled.
- CPU concurency: each CPU is associated with a private
struct softnet_datathat maintains state information. - Device drivers:
- NAPI-aware: calls
netif_rx_schdueleto adds itself to thepoll_list(instruct softnet_data).- Frames are waiting in device memory.
- non-NAPI-aware:
core/dev.c:netif_rxis called to store the recevied frame (struct sk_buff) ontostruct sk_buff_head input_pkt_queue(its size can be tuned in userspace) instruct softnet_dataand schedule the softireq that runs shortly to dequeue and handle the frames.- The actual data is copied before
netif_rxis called. Frames are waiting in a shared CPU-specific queue. netif_rxset theskb->stamptimestamp if at least one interested user (saving the timestamp has a CPU cost beacuse of the high timer resolution)- fake a NAPI-aware device (
struct net_device back_devinstruct softnet_data). The associated virtual functionpollisprocess_backlog, which process the frames ininput_pkt_queue.
- The actual data is copied before
- NAPI-aware: calls
- passes to network layer (e.g.
ipv4/ip_input.c:ip_rcv) - Congestion management
- NAPI: it is up to the driver
- Non-NAPI:
get_sample_stat()called bynetif_rx. It updatesavg_blog(average backlog size) andcng_levelinstruct softnet_data.
- maintain a
netif_receive_sbk: a helper function called bypoll()(virtual dispatching)- Netpoll client
- bonding: chang the reference to the receving interface in the
sk_buffto the group master - traffic control (
CONFIG_NET_CLS_ACT) does only use classifiers and apply actions from ingress queuing. (It may copy the fream to each registered protocol sniffer) - diverter (
CONFG_NET_DIVERT): change the L2 destination address originally addressed to others hosts to so that the frames can be diverted to the local host - bridging (
CONFIG_BRIDGE):net_bridge_portinstruct net_device - delivery to protocol handlers
- Forwarding
/proc/sys/net/ipv4/conf/<device>/forwarding/proc/sys/net/ipv4/conf/default/forwarding/proc/sys/net/ipv4/ip_forwarding
Sending Packets:
- Drivers usually use
netif_[stop|start]_queue()when the hardware buffer is full or the buffer has room again. There is a per-devier watchdog timer that resets the NIC if the device’s egree queue is disable for a long time. netif_schedule- adds device to the
Qdisc output_queueinstruct softnet_data. The devices are linked with thenet_device->next_schedpointers - Schedules the
NET_TX_SOFTIRQ(associated withnet_tx_action)net_tx_actionis called when there are devices waiting to transmit and to do housekeeping with the buffers that are not needed anymore (DMADonesignal)- deallocate the buffers in
completion_queue(instruct softnet_data). The buffer is added by drivers’ call todev_kfree_skb_irq - Call
qdisc_run
- deallocate the buffers in
- adds device to the
- queuing disciplines: the next frame to transmit is selected by the
qdisc_run- Calls the
dequeuevirutal function. - Calls
dev_queue_xmit_nit(skb, dev)if any protocol sniffers is registered. - Calls
dev->hard_start_xmit(skb, dev)vitural function: have the driver transmit a frame.- it can be a direct call for
netif_rxwhen the frame is transmitted over loopback device
- it can be a direct call for
- Calls the
core/dev.c:dev_queue_xmit(sk_buff)(similar tonetif_rx) transfer one frame from kernel’s queue to driver buffer.- Before it is called, all the information required to transmit the frame (e.g. outgoing device, the next hop, link layer addres) is ready.
- use fragmented buffer to combine the fragments if possible (scatter/gather DMA)
- compute checksum (or offload it to hardware)
- branch:
- enqueue the frame by calling
dev->qdisc->enqueue. Then tryqdisc_run - call
hard_start_xmitif the device does not use Traffic Control infrastructures.
- enqueue the frame by calling
sched/sch_generic.c:pfifo_fast_enqueue- Default queue: priority FIFO
- Disc
pkt_sched.c - IP Tos: PPPDTRCX
- PPP: precedence (ignored by Linux)
- D: minimize delay
- T: maximize throughput
- R: maximize reliability
- C: minimize cost
- X: reserved
pfifo_fast_dequeue: pass a packet to the device driver
Routing
The routing table (also called FIB) and the routing cache enable us to find the net device and the address of the host to which a packet will be sent. Reading entries in the routing table is done by callingfib_lookup(const struct flowi *flp, struct fib_result *res. (FIB: Forwarding Information Base)
There are two routing tables by default (include/net/ip_fib.h)
ip_fib_local_talbe, ID 255. A successful lookup means that the packet is to be delivered on the host itself.ip_fib_main_talbe, ID 25. A table for all other routes, manually configured by the user or routing protocols.
Both routes and IP addresses are assigned scopes.
- Host: loopback
- Link: a LAN
- Universe
Primary and Secondary address: An address is considered secondary if it falls within the subnet of another already configured address on the same NIC. Thus, the order in which addresses are configured is important.
Route actions:
- Black hole
- Unreachable: generate ICMP message
- Prohibit: generate ICMP message
- Throw: continue with the matching (used with policy routing)
IPv4
PMTU (path MTU) discovery:
- cached in associated routing table entry. The routing table cache has one single entry for each destination IP address.
- probe PMTU with DF (Don’t Fragment) flag set. If it is larger than the optimal size, the sender will receive
ICMP FRAGMENTATION NEEDED.
There are many problems with fragmentation, so the IPv6 decided to allow it only at the originating hosts, and not at intermediate hosts such as routers, NATs.
Multicast Routing (IPMR)
Software Forwarding
Interface between control and forwarding planes:
- Linux:
- old: /proc, sysctl, ioctl
- new: netlink
- BSD:
- routing socket
- OpenFlow: SDN for L2
XFRM
xfrm is an IP framework for transforming packets (such as encrypting their payloads). This framework is used to implement the IPsec protocol suite. It is also used for the IP Payload Compression Protocol and features of Mobile IPv6.
IPsec is a useful feature for securing network traffic, but the computational cost is high: a 10Gbps link can easily be brought down to under 1Gbps, depending on the traffic and link configuration. Luckily, there are NICs that offer a hardware based IPsec offload which can radically increase throughput and decrease CPU utilization. The XFRM Device interface allows NIC drivers to offer to the stack access to the hardware offload.
Userland access to the offload is typically through a system such as libreswan or KAME/raccoon, but the iproute2 ip xfrm command set can be handy when experimenting.